Building the Funda Harvester
Voor het nieuwe database-thema van de opleiding hadden we een grote database nodig: eentje waarmee we de studenten de noodzaak van een goed datamodel konden aanleren, en de noodzaak van goed uitnormaliseren konden demonstreren. De database die de studenten zouden krijgen, zou daarom behalve behoorlijk groot ook behoorlijk onhandig in elkaar moeten zitten, zodat er veel aan te verbeteren viel.
Op zich zou de database die we in het huidige database-thema gebruiken wel hiervoor ingezet kunnen worden. Dit betreft data van de bekende makelaarssite Funda die ik jaren geleden (ik denk 2008) eens heb geharvest een collega van me jaren geleden (ik denk 2008) eens heeft geharvest. Maar omdat ik die oorspronkelijke harverster niet zo 123 terug kon vinden (en omdat die het waarschijnlijk toch niet meer zou doen), dacht ik dat dit een mooie gelegenheid was om een nieuwe te schrijven.
Nu schijnt er wel een API geschreven te zijn voor Funda, maar die was niet zo heel eenvoudig te vinden. en wat ik er even over heb gelezen is deze alleen beschikbaar voor makelaars, of moet je er sowieso een API-key voor hebben. Een andere site biedt wel een redelijke API aan, maar die scheen meer gericht te zijn op ontwikkelaars die huizen op hun site willen hebben, en niet per se voor het harvesten. Nu had ik die natuurlijk wel kunnen gebruiken, bijvoorbeeld door deze via een Python-scriptje aan te roepen, maar in het kader van waarom makkelijk doen als het leuker kan besloot ik toch de boel met Java te gaan binnenhalen.
1. Parseren van de funda-site
Het idee van de harvester is niet zo ingewikkeld: we halen de html van de site binnen en lopen daar doorheen op zoek naar de data die ons interesseert. Ik begon met individuele huizen, met de gedachte dat als ik één huis kon opslaan ik ook wel tienduizend huizen zal kunnen opslaan.
De pagina van Funda waar de data van een specifiek huis wordt weergegeven is verrassend leesbaar. Alle gegevens staan in een div die class object-kenmerken-body heeft (figuur 1). De opzet van deze div is behoorlijk rechtdoorzee: elke waarde wordt hier weergeven als key-value-paren (listing 1)
<dt>Aangeboden sinds</dt> <dd>5 weken</dd> <dt>Status</dt> <dd>Beschikbaar</dd> <dt>Aanvaarding</dt> <dd>Beschikbaar in overleg</dd>
Listing 1
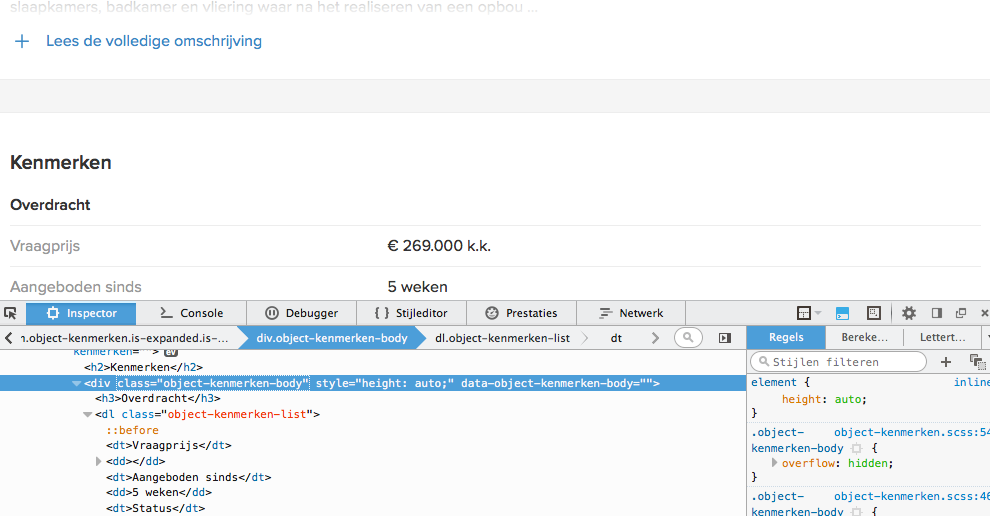
De leesbaarheid van de Funda-html.
Ik maakte een class HuisPagina die feitelijk een in-memory representatie van de online pagina moest gaan worden. Binnen deze class zou ik dan eenvoudig met XPath de betreffende div kunnen opzoeken, waarna ik dan binnen die context alle <dt>’s zou opvragen. Deze <dt>’s zouden als keys optreden, en de next-sibling hiervan als value. Dit leek een vrij eenvoudige opgave, maar het lukte me niet direct om zowel de node als de next-sibling te selecteren (nu moet ik er wel bij zeggen dat het al een tijdje terug was dat ik XPath had geschreven, dus dat was wat roestig). Uiteindelijke besloot ik dus maar een brute-force oplossing te gebruiken – namelijk door gewoon binnen de context zowel de <dt>’s als de <dd>’s op te vragen en hier overheen te itereren en een NodeList van te maken. Een eenvoudige check op de lengte van deze twee zou dan moeten aangeven of iets mis was gegaan (Listing 2):
XPath xpath = XPathFactory.newInstance().newXPath();
XPathExpression kenmerk = xpath.compile("//div[@class='object-kenmerken-body']");
Node kenmerken = (Node)kenmerk.evaluate(huis, XPathConstants.NODE);
NodeList typeList = getTypeOrData(xpath, kenmerken, "//dt");
NodeList dataList = getTypeOrData(xpath, kenmerken, "//dd");
if (typeList.getLength() != dataList.getLength()) {
throw new Exception("type and data are not of the same
}
Listing 2
Die getTypeOrData(XPathContext, Node subTree, String typeOrData) haalde ofwel de <dt> ofwel de <dd> uit de betreffende subtree:
private NodeList getTypeOrData(XPath context, Node subTree, String typeOrData) {
NodeList rv = null;
try {
XPathExpression expr = context.compile(typeOrData);
rv = (NodeList) expr.evaluate(subTree, XPathConstants.NODESET);
} catch (Exception e) {
e.printStackTrace();
}
return rv;
}
Helaas bleek bij uitgebreid testen dat de funda-site in sommige gevallen een lege <dd> of <dt> introduceerde – waarbij deze brute force oplossing natuurlijk niet meer werkte. Dus toch maar netjes de XPath-expressie uitzoeken om voor elke <dt> de next-sibling dd op te halen:
String keyMatcher = "//dt[not(@*)]"; String dataMatcher = "//dt[not(@*)]/following-sibling::dd";
Daarmee werd deze methode gelijk een stuk robuster en transparanter. In plaats van de relatief onbekende NodeList kon ik nu direct een HashMap<String, String> terugsturen.
Behalve deze data moest ik natuurlijk ook het adres en de beschrijving zien te vinden; die stonden namelijk niet in deze div. Ook hier hielp Funda weer door de pagina’s goed te structuren: het adres stond in de h1 met class="object-header-title", en de postcode en woonplaats in de span class="object-header-subtitle".
String adres = getSpecificNodeValue("//h1[@class='object-header-title']");
String pc_wp = getSpecificNodeValue("//span[@class='object-header-subtitle']");
In het kader van two or more, use a for, maakte ik een methode die vanuit een opgegeven String de inhoud van die bepaalde node teruggeeft (Listing 3):
private String getSpecificNodeValue (String node) throws Exception {
String rv = "";
XPath xpath = XPathFactory.newInstance().newXPath();
XPathExpression exp = xpath.compile(node);
Node desc = (Node)exp.evaluate(huis, XPathConstants.NODE);
rv = desc.getFirstChild().getTextContent();
return rv;
}
Listing 3
De beschrijving van het huis stelde me nog wel voor een paar problemen. De methode getTextContent van javax.xml.xpath houdt op zo gauw er een nieuwe regel in de inhoud van de node staat, en omdat deze tekst bijna altijd over verschillende regels loopt, kreeg ik initieel alleen maar de eerste regel. De specifieke methode om alle inhoud te krijgen bleek getTextContent() te zijn. Deze methode geeft echter niet de html terug, die vaker wel dan niet in de beschrijving van het huis voor komt. Na enig zoeken kwam ik er achter dat er in xpath geen equivalent bestaat voor innerHTML (wat in JavaScript zou werken), dus besloot ik het er vooralsnog maar hier bij te laten. Wel een beetje jammer dat we de formatting van de beschrijving van het huis kwijtraken, maar dat is dan niet anders.
Wat ik nog wel graag wilde was de mogelijkheid om de positie van het huis op een kaart te plotten – dat is in een later stadium wellicht een mooie opgave voor de studenten. Door even in de html te zoeken op google.maps kwam ik al snel achter de positie van deze gegevens (Listing 4):
<div class="object-map-canvas" data-object-map-canvas
Kaart laden...
<script type="application/json" data-object-map-config>
{
"lat": 52.00932,
"lng": 4.978898,
"markerTitle": "Dorp 192",
"markerUrl": "//assets.fstatic.nl/855/assets/components/object-map/punaise.png"
}
</script>
<noscript>
<img alt="Dorp 192 op de kaart" src="https://maps.googleapis.com/maps/api/staticmap?center=52.00932,4.978898&amp;zoom=15&amp;size=500x192&amp;scale=2&amp;markers=color:0xF8B000%7C52.00932,4.978898" class="object-map-static">
</noscript>
</div>
Listing 4
Het is mooi om te zien dat Funda een fallback heeft voor mensen die geen JavaScript in hun browser hebben (in de vorm van een statisch plaatje) en ik heb even overwogen om dit plaatje te harvesten in plaats van de latitude en longitude. Maar dat maakt de kaart minder flexibel, dus toch maar die lat en long uit het stukje JavaScript. Gelukkig was dat de enige plek waar application/json als type voorkwam, dus ik kon het mooi daarop matchen – met hergebruik van de methode getSpecificNodeValue(String pattern), waaruit maar weer eens het nut van abstraheren blijkt. En even een beetje rommelen met wat reguliere expressies leverde vrij snel het gewenste resultaat (Listing 5):
private String getLatLng (String latlng) throws Exception {
String rv = "";
String json = getSpecificNodeValue("//script[@type='application/json']");
String newj = json.replaceAll("(\\r|\\n)", " ");
newj = newj.replaceAll(" +", " ");
Matcher m = Pattern.compile(".*" + latlng + "[^\\d]+([^,]+).*",Pattern.MULTILINE).matcher(newj);
if (m.matches()) rv = m.group(1);
return rv;
}
Listing 5
Alles bij elkaar was ik nu in staat om van de html van Funda een Java-object te maken dat een huis representeerde. De eigenschappen van het huis werden zo veel mogelijk in een HashMap opgeslagen en waar dat niet kon als separate properties van het object.
martijn emons
bart
Steven
bart
Pingback: bettercodehub | Over kunst, filosofie en techniek
ad
Chris Zeinstra
bart