2. Maken van een woonobject
Nu ik een Java-object kon maken dat een woning kon representeren, was de volgende stap uiteraard om die in de database op te slaan. Voor het betreffende thema gebruiken we in de eerste paar weken Oracle en in de laatste paar weken mysql: deze database moest dus in mysql worden opgeslagen – en, zoals gezegd, zo onhandig mogelijk. Ik besloot dus om de boel op te slaan in twee tabellen: één met het adres en de omschrijving van de woning en één met alle attributen onder elkaar, gekoppeld via een foreign key (Figuur 2).
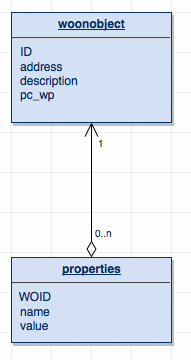
ERD van de initiële database.
Ik had natuurlijk de hele boel gewoon naar mysql kunnen verplaatsen, maar omdat dit project bedoeld was om iets relatief eenvoudigs zo ingewikkeld mogelijk op te zetten leek het me voor de hand te liggen om dit in JPA te doen. Door de betreffende class van annotaties te voorzien, zorgt JPA voor de opslag in de database.
Het was nog even gedoe om ervoor te zorgen dat de persistentie inderdaad in mysql gebeurde; de meeste voorbeeldcode die online te vinden is slaat de data native op in een objectdb. Gelukkig vond ik op github vrij snel een link waarin de juiste settings voor het persistente.xml bestand voor mysql in stonden weergegeven. Het was ook nog een behoorlijke puzzel om uit te vinden waar dit bestand exact moest staan, want daarover verschilden de meningen ook nog hier en daar. Uiteindelijk werkte het wanneer ik het in de directory META-INF in het classpath zelf zette – wat me verbaasde, want die directories heb je eigenlijk alleen maar als je met application servers te maken hebt.
JPA werkt vrij goed. Je geeft per propertie van de class aan dat deze in de database moet komen en in welke kolom. Om bijvoorbeeld het adres, de postcode en woonplaats van het woonobject (wat allemaal Strings zijn) in de database op te slaan, gebruik je de volgende annotaties:
@Column(name="address") private String address; @Column(name="pc_wp") private String pc_wp;
Listing 6
De properties van het woonobject die ik in de tweede tabel wilde opslaan, worden in het Java-object opgeslagen in een HashMap. Omdat dit een 1:n-relatie betreft, moet hier wel een tweede tabel aan te pas komen. Hiervoor heeft JPA ook een aparte notatie (Listing 7):
@ElementCollection @MapKeyColumn(name="name") @Column(name="value") @CollectionTable(name="properties", joinColumns=@JoinColumn(name="WOID")) private Map<String, String> properties;
Listing 7
Hiermee geef ik aan (regel 4) dat deze Collection in de tabel properties terecht moet komen en dat deze via de waarde in de kolom WOID gekoppeld worden aan het object waar het bijhoort (de foreign key). Ik geef verder aan (regel 2) dat de key van de HashMap in de kolom name moet worden opgeslagen, en (regel 3) de value in de kolom value. In de documentatie wordt één en ander goed beschreven.
Er is evenwel een aantal zaken die wat lastiger zijn dan dat. Allereerst de omschrijving van het huis in kwestie. Hoewel deze, net als de postcode of de woonplaats, in een String wordt opgeslagen, kan deze evengoed behoorlijk lang zijn. Het probleem is evenwel dat een String door JPA standaard wordt gepersisteerd in een varchar(255) (terwijl de maximum lengte van een String 231-1 is; dit is een mooi voorbeeld van de Problem of Granularity in de Paradigm Mismatch). Om dit probleem op te lossen, moest ik de omschrijving van het woonobject een aparte annotatie meegeven: @Lob (ik vermoed van Large Object, de documentatie is hier niet helder over):
@Lob @Column(name="description") private String description;
Listing 8
Een tweede punt waar ik over viel was dat er steeds maar één woonobject in de database terecht kwam, terwijl ik inmiddels zo ver was om de boel te testen met twee pagina’s van Funda. Initieel dacht ik dat dat kwam omdat de primary key van de objecten ofwel steeds dezelfde was ofwel werd overschreven. Een primary key geef je in JPA aan met de annotatie @Id @GeneratedValue. Volgens de documentatie kun je hier nog wel een stategy aan meegeven, maar zou het standaard moeten werken conform de eigenschappen van de database (mysql heeft bijvoorbeeld een auto_increment). Verschillende waarden van de strategy leverden geen verbetering op: er bleef maar één object in de tabel verschijnen.
Tijd om verder te kijken. Standaard geeft JPA alleen maar wat informatie over connecties en dergelijke, maar door de onderstaande regel in persistence.xml toe te voegen (Listing 9), kreeg ik de volledige sql te zien.
<property name="eclipselink.logging.level" value="FINE"/>
Listing 9
Toen ik deze output aandachtig had bestudeerd, kwam ik er achter dat elke keer wanneer er een nieuw object werd toegevoegd, de hele database werd vervangen. Dat klopte ook, want dat stond in eveneens in persistence.xml; de instellingen die ik van github had gehaald, gingen er van uit dat je maar één keer de data in de database zou stoppen:
<property name="eclipselink.ddl-generation" value="drop-and-create-tables" />
Uit de documentatie bleek al snel dat ik de value van deze property-tag moest vervangen door create-or-extend-tables. Inderdaad kreeg ik nu keurig twee objecten in de database wanneer ik twee huis-pagina’s van Funda invoerde.
Een laatste punt waar ik tegenaan liep was dat ik om de haverklap een nullpointer-exception kreeg. Enige onderzoek leerde dat het kwam uit de HashMap die door de huisparser wordt gevuld (Listing 10):
for (int i=0; i<typeList.getLength(); i++) {
String type = typeList.item(i).getFirstChild().getNodeValue();
String data = dataList.item(i).getFirstChild().getNodeValue();
rv.put(type.trim(), data.trim());
}
Listing 10
Wanneer ik hier op regel 1 getLength() verving door een getal onder de 9 ging het wel goed. Het bleek dat het negende element voor de key geen waarde kon vinden in de html van Funda (omdat deze waarde een niveau dieper bleek te liggen). Ik had geen zin om de XPath nog verder uit te werken, dus besloot eenvoudigweg een check te doen op de waarde van type en data: als die Strings leeg waren of niet bestonden, zou die eigenschap van het huis niet worden opgenomen. Ik verving regel 1 dus door de onderstaande code, die een methode aanroept om de check op die Strings te doen (Listing 11):
// vervanging van regel 5
if (StringsAreOk(type, data)) rv.put(type.trim(), data.trim());
//methode om te checken of de Strings ok zijn:
private boolean StringsAreOk(String... str) {
for (String test: str) {
if (test == null || test.equals("")) return false;
}
return true;
}
Listing 11
Ik had nu een object dat ik kon opslaan in de database. Tijd om de hele boel aan elkaar te knopen.
martijn emons
bart
Steven
bart
Pingback: bettercodehub | Over kunst, filosofie en techniek
ad
Chris Zeinstra
bart