Communicatie tussen deze twee lagen
Nu had ik een object dat een huis van Funda kon representeren, en een object dat dat kon persisteren. Het was dus zaak deze twee met elkaar in verband te brengen. Natuurlijk zou het eenvoudig geweest zijn om het object gewoon zelf in de database op te slaan, maar omdat zowel het harvesten als het opslaan de nodige tijd vereiste, leek het me beter om daar twee aparte processen van te maken, met een message queue hiertussen.
In het onderwijs zijn al verschillende message queues ter sprake gekomen, maar RabbitMQ komt altijd als één van de betere systemen uit de verf. Een message queue met weinig footprint en eenvoudig op te starten. Het ding draait op Erlang, maar als je dat niet hebt geïnstalleerd komt dat mee met de disk image. Eenvoudig downloaden en opstarten.
RabbitMQ verstuurt feitelijk byte-arrays over de lijn, dus ik moest heb huis-object serialiseren. Om dit aan de ene kant te kunnen doen, en aan de andere kant van de lijn weer te kunnen deserialiseren definieerde ik een interface Perisitable (Listing 11):
public interface Persistable {
public byte[] getBytes();
public static WoonObject fromBytes(byte[] body) {
WoonObject obj = null;
try {
ByteArrayInputStream bis = new ByteArrayInputStream(body);
ObjectInputStream ois = new ObjectInputStream(bis);
obj = (WoonObject) ois.readObject();
ois.close();
bis.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
}
return obj;
}
}
Listing 11
Het is het WoonObject die deze interface implementeert, omdat dat is wat er uiteindelijk over de lijn gestuurd gaat worden. Allereerst de methode getBytes(): die serialiseert eenvoudig het huidige object naar een byte-array, die vervolgens over de lijn gestuurd kan worden (Listing 12):
public byte[] getBytes() {
byte[] bytes;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try {
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
oos.flush();
oos.reset();
bytes = baos.toByteArray();
oos.close();
baos.close();
} catch (IOException e) {
e.printStackTrace();
bytes = new byte[]{};
}
return bytes;
}
Listing 12
Het is de class Sender die deze methode aanroept en het resultaat hiervan over in de queue zet (Listing 13); op deze manier kan de harvester rustig verder met de volgende pagina terwijl de Persister ervoor zorgt dat de objecten in de database terecht komen. Deze Sender maakt eerst connectie met de message queue en stuurt vervolgens het geserialiseerde WoonObject daar naartoe:
channel.basicPublish("", Settings.QUEUE_NAME, null, obj.getBytes());
Aan de andere kant van de lijn is een Receiver-class die de byte-array ontvangt. Hier maak ik gebruik van de mogelijkheid die Java8 biedt om in een interface een implementatie van een methode op te nemen. De static method fromBytes() hierboven (Listing 11) krijgt als parameter een byte-array en maakt hier weer een WoonObject van (dit is feitelijk een implementatie van het Decorator-pattern).
De Receiver-class is relatief eenvoudig: deze consumeert het object in de message-queue, roept de methode fromBytes() aan en cast het resultaat hiervan naar een WoonObject (omdat ik alleen WoonObjecten verstuur kan dit zonder problemen), die vervolgens gepersisteerd wordt.
WoonObjectImpl foo = (WoonObjectImpl)Persistable.fromBytes(body); Persister.setUp(); Persister.persistObject(foo); Persister.tearDown();
Listing 13
Hieruit blijkt wel de noodzaak van dat WoonObjectImpl zowel WoonObject als Persistable implementeert: vanuit de eerste weten we dat het object gebruik maakt van JPA en de tweede zorgt ervoor dat het over de message queue gestuurd kan worden (eigenlijk moet die interface dus hernoemd worden naar Transferable). Als het object dat is binnengekomen is gedeserialiseerd, kan ik eenvoudig de JPA methodes daarbinnen aanroepen om het in mysql op te slaan. Het totale plaatje ziet er uiteindelijk als volgt uit (Figuur 3):
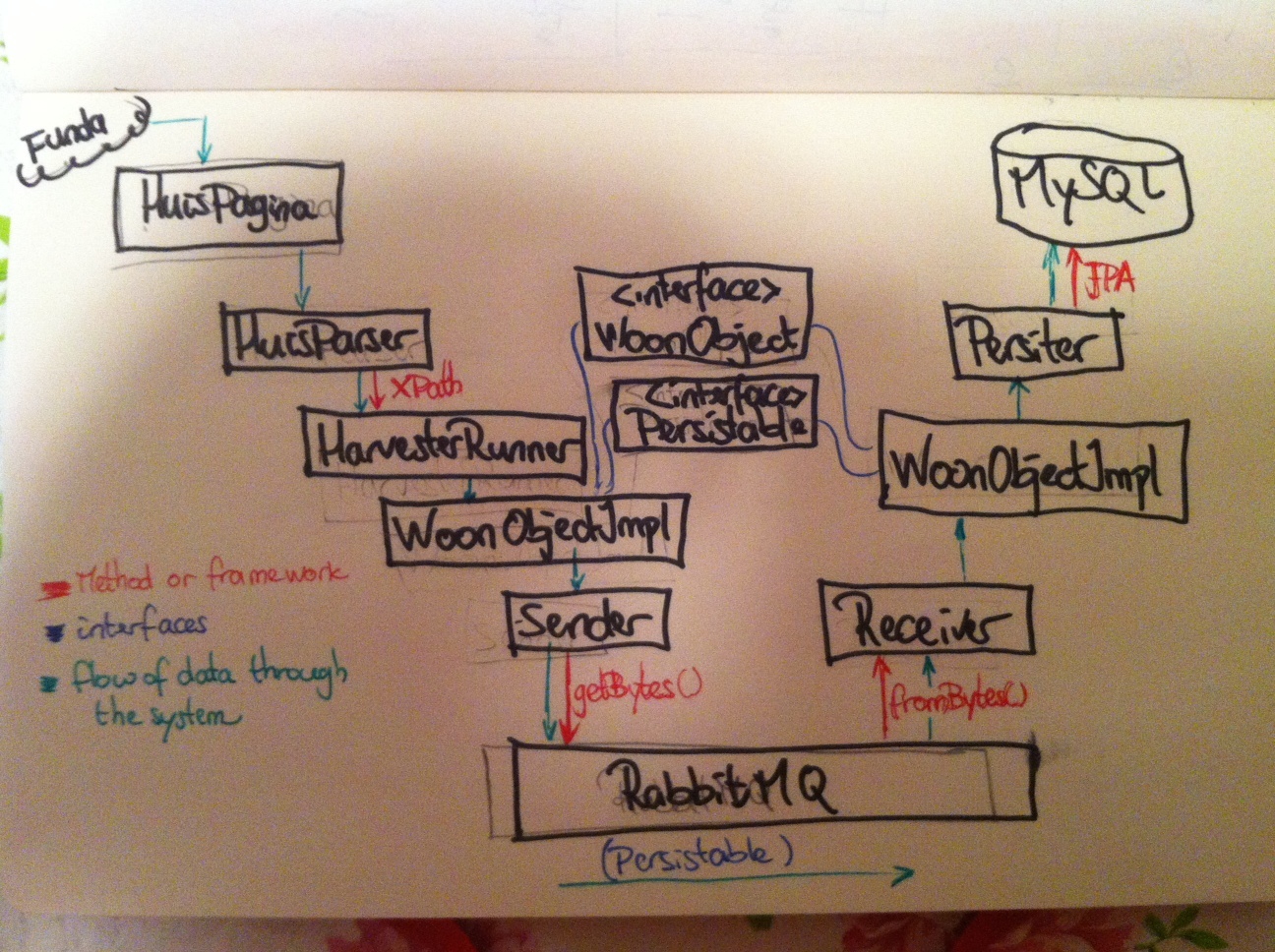
Uiteindelijke architectuur.
Op deze manier kon ik een heel stuk van de Funda-database harvesten, zonder dat één van beide kanten last had van falende performance. Het is misschien een aardige extra opgave voor de eerstejaars studenten om deze code te analyseren en te verbeteren, maar vooralsnog doet het systeem prima waar het voor gemaakt is.
martijn emons
bart
Steven
bart
Pingback: bettercodehub | Over kunst, filosofie en techniek
ad
Chris Zeinstra
bart